Types of Tests for AI Systems #
At a simple level, evals are how we test AI systems, but the term “evals” covers a lot of ground. In reality there are lots of types of tests mainly grounded in an ML background. Let me explain. First there’s online vs offline, then there’s human vs LLM-as-a-judge, so that gives us 4 flavors off the bat. Plus there’s RAG which looks more like search bench-marking with it’s accuracy, precision, and recall. On top of these there are a variety of standard testing approaches and styles.
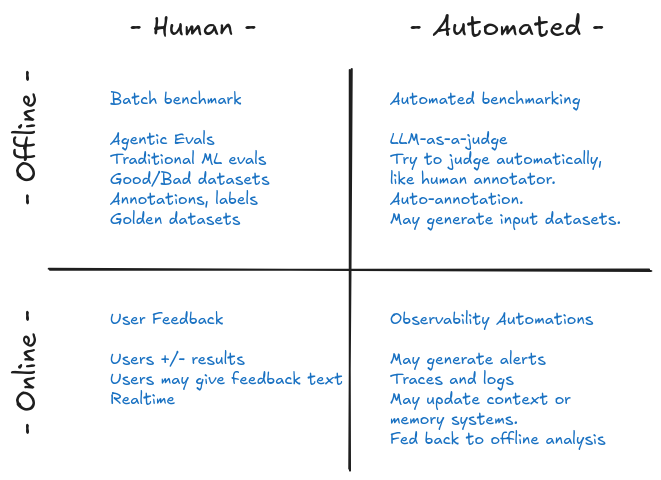
Diagram: What you see here is Human vs Automated on the horizontal axis, which naturally separates between the manual human curate work, and the more involved automations where serious time and data need to be employed to get the best results. Similarly, we have Offline vs Online where the offline is happening on a developers bench (laptop or staging) and online is live in real-time with users or close to it.
- Human Offline: here a developer is kicking off a benchmark or test run of some kind. In traditional ML you may be use test-evals the same way you would if testing a model you’ve been training. You have golden, ground truth, expected results –both positive and negative feedback. If not binary, you may have many labels, like is this image “pizza” or “hotdog”, so this is when the work is generally supervised.
- Automated Offline: This is the next level, where you write a prompt to judge the output. You probably still do all the other things, but with the LLM-judge your trying to extend the human reviewers for leverage. This can also extend the inputs by generating synthetic random data and also judging that. Ideally you have occasional human supervision (like RLHF) but you’re probably finding cases that go back into your golden data set.
- Human Online: Here is where you have live feedback. When you get to this stage you have probably grown to the point where the scale has overwhelmed the humans. You’ve placed buttons on the UI for thumbs up / thumbs down feedback, maybe even provided a way for users to write about their reasoning, expectations, and intentions. This is the parallel to filing an AI “bug report” for review –maybe even automated flagging.
- Automated Online: The is the automated equivalent. You may have a judge that looks are a sampling of conversations to detect unusual cases for further review. At this point, you have logging and traces (spans). Information, like high latency or cost automatically flag cases for review, without the user calling out poor performance.
This covers a lot of ground, but I need to mention one more:
Conversations (Chats): these are hard to test and can follow many paths through an agent and tool calls. The best method I’m aware of is what I call Bot-Tests, and I’ve heard called LLM-as-a-user, persona tests, multi-turn conversation tests, etc. Here you set up an agent to converse as if it’s a user with enough background on how you’d like the conversation to evolve. A great example is in the medical context. Imagine you setup an agent to act as a patient with a specific illness, but to pretend it doesn’t know what the illness is, then gradually exhibit more and more symptoms.
Code #
A prompt A test - generic good bad llm-judge - a prompt, then a rubric llm-jury - a set of perspectives
test2
References and Resources: