tl;dr become prod-ready and bullet-proof using agentic evals testing.
Those of us who write AI applications fall into two categories: the nervous and the prod-ready. It’s usually based on whether you have run a production system, with real users, over time. When you have, you learn the first key differentiator is “evals”, but not specifically traditional ML evals. Simply put, it’s whether you have an automated way to test and score the quality of your systems.
A year ago, I was working on several projects, and one needed a much higher degree of quality and attention because it was medical. The project was 100% about trust. Not only did it need to be highly accurate, but it had many moving parts including over a dozen agents. My fellow developer did an amazing job of making it accurate, thorough, and consistent. There were a few key tricks to make this coordination work well, but what really taught me was how important having agentic evals are for making a high quality system. In fact, your agentic evals are more valuable IP than your prompts because they capture the true intent whereas prompts are changeable implementation details.
Fundamentals #
TDD: Test-Driven Development, at its core, has a simple principle:
- Write a test that fails, then code until it works.
We still need this safety net, but with AI systems, the results are far less binary, so we often need a score or a full rubric to know when we’ve reached our goals. Unittests that pass or fail is a start, but too brittle with AI work. Whether or not a project has agentic evals is a clear signal (like a code smell) about its production readiness.
When working on any system you need a way to answer “Does it work?” and with AI “Does it work well?”, so the definition of done has shifted a little.
Evals: ML work and agent system development are different enough that the existing tools don’t quite fit. ML evals are the common tool today to achieve quality testing, and they’re a natural fit for those coming out of ML research and engineering. If you’ve trained a classifier, model, or even a trivial neural net, you’ve probably used ML evals. But these are designed for a different problem where you have lots of input data. When writing a prompt, agent, or workflow of agents, you’re starting with a bit of test data and growing it over time. Current eval tools often feel heavyweight for this situation.
So, I’m calling out something between TDD unittests and ML evals. If they got married today, their kid would be agentic evals –some of each. They’re the blend of “Make it work” and “Make it right” for AI. (thanks Kent Beck).
When I say “agentic evals”, I’m simply talking about these principles:
- A way to score your output.
- A set of inputs to test.
- A fast and simple way to run this.
Don’t get me wrong, if you wrote ML evals using existing tools, you rock! and you’re already ahead of the game. But if you’re just starting out, you might find it easier to start with agentic evals.
Problems at Every Stage #
Let’s go over some of my past failure. If you don’t have measures and metrics, a myriad of problems come up at every phase of development:
Problems you hit in Dev #
When your team is first writing the application, and trying to reach that crucial step of getting the minimum feature set functioning:
- Prompt Churn: You keep changing the prompt to “make it work” but with every prompt change you might improve the output for one input, but hurt other cases. This is a game of whack-a-mole where fixing one problem reverts progress on others.
- Error Amplification: In a prompt change, a shift early in the pipeline causes downstream agents to different inputs, and with each step errors grow. This is like a game of telephone, where the output gets worse and less predictable as the chain gets longer.
- Prompt Bloat: In an attempt to handle different inputs the prompt keeps growing because you’re afraid to update the start of the prompt. You may even wind up with a prompt that contradicts itself if many people on your team are contributing. Ultimately, you’ll even cause the context window to grow too large and the LLM will be unable to pay attention to all of it when trying to get something done (see context-rot below).
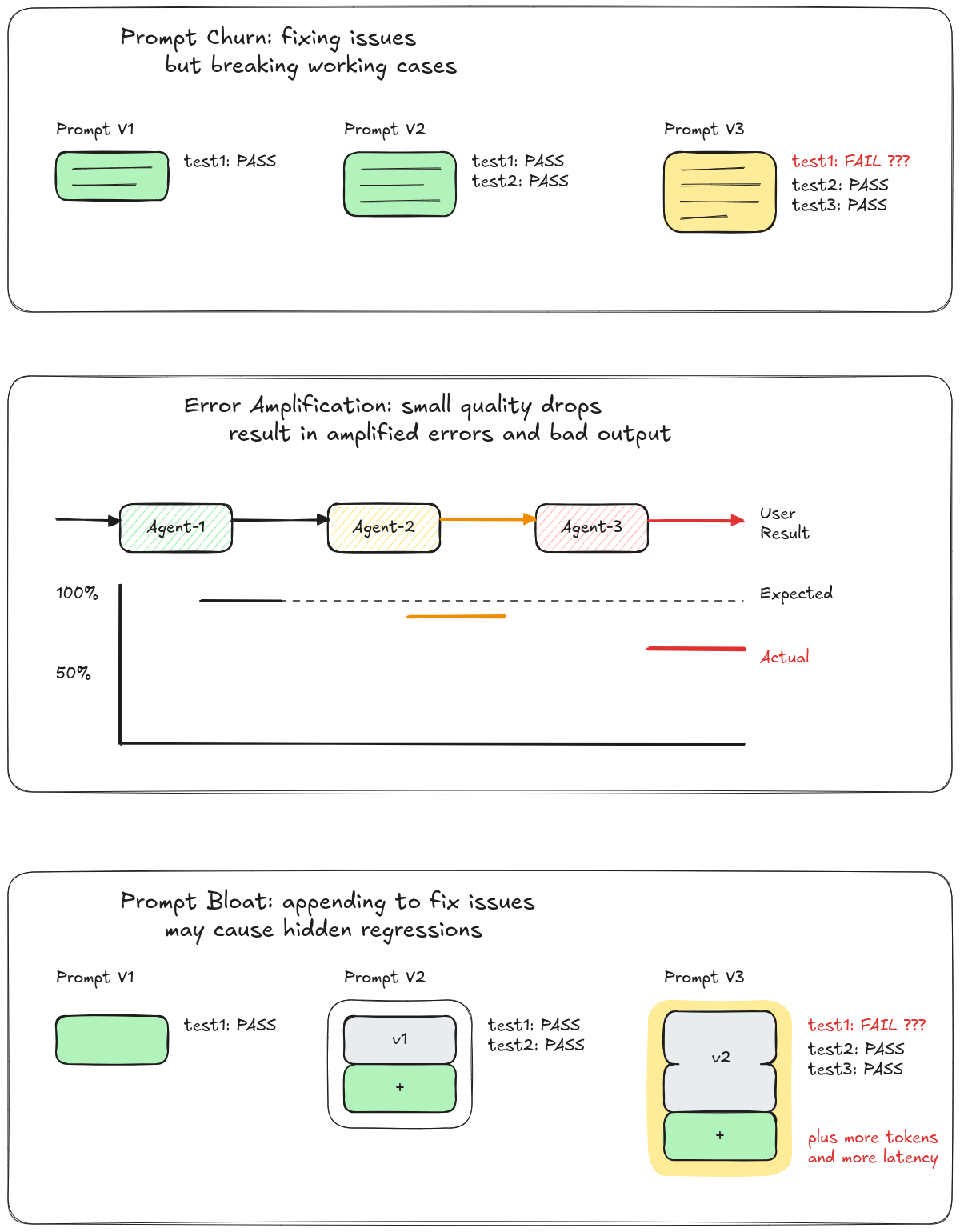
How Agentic Evals Help:
- Prompt Churn: Agentic evals testing gives you a set of inputs that you can re-evaluate when the prompt changes to ensure your old fixes aren’t regressing. Every bug fix then becomes durable. You can see when you cause a test case to regress.
- Error Amplification: You can tell when your agentic pipeline gets worse, and you can dig into which prompt degraded and it’s downstream effect.
- Prompt Bloat: now you have a way to verify if trimming the prompt hurts your score, so you can be confident your update is safe.
Problems with Beta Testing #
You finally get a working system in front of real users, and start getting real feedback.
- Change Fear: You want to fix something a user has called out, or handle a new case, but you’re afraid to make a change (see prompt churn). It feels like a house of cards –too fragile to touch.
- Cost Control: Now that you have real users you’re shocked at how much tokens are costing you. You wish you could decrease the context size of your prompts but you don’t know if that’s safe. Maybe you could use a smaller cheaper model or an open-source model, but again you don’t know if that’s safe. This is the difference between having a profitable business and being out of business. Looking at your budget, your new airplane is outta-runway, and you probably have to move forward, burning through investor money to prove your product-market-fit.
- Tooling: You likely have tool-calling (tool-use) and maybe MCPs but since you didn’t develop these, you discover their short comings as you go. Now you realize your
WebFetchToolonly grabs the first 8k of a web site, etc. This is another issue you discover but have to table until your startup has income. - Timeliness: Because the development process takes time, staleness creeps in. For example, you built based on web pages that got updated, or other data that are growing. Now you realize you need to re-test with newer data but have to go through that manually. Maybe you even used a model that was trained half a year ago so you absolutely need to add a web tool to get up-to-date news, or you need to switch to the latest greatest frontier model. Neither of which feels safe. Your product is in danger of being past its sell-by-date.
- Focus: The map is not the territory. You had a theory about what’s valuable to your users. Putting it in front of people changes all that, plus you learn about a lot of problems you hadn’t considered. Now your prompt is trying to juggle too much, so you’re wondering if you can safely update it to handle the new use cases in one agent, or if you need to split the work up into separate prompts or agents.
How Agentic Evals Help:
- Change Fear: Handling new cases, you’re sure you haven’t hurt old cases.
- Focus: Splitting a prompt in two becomes safe. The tests are the same, it’s just the implementation that changes.
- Timeliness: Testing with a new model is easy, so you can safely upgrade to one of the latest frontier models.
- Cost Control: You have tests to let you try out smaller cheaper models, or understand where they fall down and need better prompts.
- Tooling: You will naturally catch shifts in tool calls that impact your quality, as well as having a way to try different tools safely.
Problems in Production #
You’ve ironed out a lot of issues by this stage and you’re finally going GA with a full launch. Now it’s hard to respond to folks individually and understand how all your users are doing.
- Flying Blind: Things go well and you grow like crazy. But with alerts and logs you only investigate the most severe issues. Things feel fragile, like the next update could accidentally trigger a surprising amount of user churn. You find you’re randomly digging into your trace spans to figure out how little problems are causing error amplification.
Then Context-Debt: As real user data builds up, which is great, it creates more context to manage going into your prompts. It feels like tech-debt, where you have a nagging demon on your shoulder that you don’t have time to banish. The data build up has lots of negative side effects, and it’s time for some serious context engineering:
- Latency Hit: In turn, this slows down answer latency and TTFT (time to first token). You’re like a cooking frog, the slow down is getting gradually worse over time, so you don’t notice you’re boiling, until your CEO realizes too late that it’s caused a big customer to leave.
- Context Costs: The context window has a direct relationship to tokens and costs, which just keeps creeping up. Perhaps the worst part is it affects the best and most loyal customers the most.
- Context Rot: For the same reason (this context build-up), the context windows filling up cause the LLM to lose track of what it’s doing and emit really poor results. Now you have to scramble to implement a better context compression scheme and a real memory sub-system for your use-cases.
How Agentic Evals Help:
- Latency Hit: In addition to quality scores, measuring timing is something you get easily. Now you can detect latency changes and make smart trade-offs.
- Context Rot: Likewise you can be very intentional about how you trim your context, and you have a basis for selecting a memory subsystem, for example.
- Context Costs: The same is true for tokens (and input and output length); they’re all easy to track with agentic evals.
From Newbie to Prod-Ready #
When building a project or managing one in production, you want a lot of safety nets. But take just this one critical step first.
These agentic evals are lightweight compared to ML evals, which are a big scary thing (unless you’re accustomed to ML research). If you try out some of the tools you’ll find them daunting. But there’s an easier first step, that can naturally fall out of the process of writing and trying out the initial prompts. If you already have code, that’s okay too, you may even have a CSV with a pile of inputs to try out, or just a spreadsheet of inputs and outputs.
The key is just to start. Once you have something, every bug fix or PR can check the score, and your tests will naturally evolve.
How to start and what to build
- A way to score your output.
- A set of inputs to test, and optionally outputs
- A fast and simple way to run these, like a benchmark.
Scoring: This could be code that checks a regex, but it often becomes a single prompt with a clear rubric, which we’ll call an LLM-judge, or it could be a panel of agents that review and score different aspects of the results, aka the LLM-jury. To start, it may help to keep thinking binary and have the judge fail when there’s some clearly bad output.
Inputs: Although you may hard code these initially, often these grow into either a CSV file, or a directory with a test input per file. This makes it trivial to add more cases, for the whole team. Later down the line, this can be a simple database or other data store so you can build better tooling and automation.
Benchmarking: Just a test runner, so even pytest (pytest-benchmark) can be a useful starting point. Often these are easy enough to quickly vibe code, which can make the outputs help track timing and token costs. As you level up, you’ll tie this into CI/CD so that PRs that cause any regressions are nicely called out.
Your First Agentic Eval
- 5-10 inputs in a CSV file.
- A judge prompt that catches one problem.
- A script to run it.
Lots more to say, but I’ll stop here so you can let me know what you’d like to talk about next.
Thanks!
Thanks: Kent Beck, Tomislav Čar